



 AI/ML
AI/ML  Software Development
Software Development 



8 Popular Machine Learning Algorithms for Predictive Modeling
Have you ever wondered how companies can accurately predict future trends and behaviors? The answer lies in the potential of machine learning algorithms in predictive analytics.
Machine learning is revolutionizing the way we analyze data and make informed decisions—from predicting stock prices to detecting fraudulent activity.
In this article, we will focus on basic ML algorithms. We will discuss their types, how they work, and the steps involved in creating and training your own models.
Table of Contents
What are Machine Learning Algorithms?
Machine learning algorithms are mathematical models trained on data. They use statistical and predictive analytics techniques to learn patterns and relationships within the data. Then, they use this knowledge to make predictions or take action on new, untested data.
The main advantage of these algorithms is their ability to process training data to new, previously unknown forms, allowing them to make accurate predictions in real-world scenarios.
Algorithm Selection Criteria
Choosing the right algorithm depends on many variables. Even the most experienced data scientists cannot pinpoint the best algorithm without first testing it on a specific dataset. Therefore, the choice is largely speculative without initial testing of several algorithms on the given data.
However, there is a set of rules that, based on several variables, help you narrow down your search to 2-3 algorithms that best fit your particular case. You can then test these selected algorithms on a real dataset to ensure that making the right decision becomes a formality.
1. Type of Task
We usually start with the simplest methods to determine if it’s necessary to proceed with more profound and complex algorithms. First, we analyze the type of task at hand. Is it a classification task where we want to predict specific categories? Or is it a regression task where we aim to predict continuous values? The better we understand the nature of the task, the more accurately we can choose the appropriate algorithm.
2. Size and Type of Data
Understanding the data is key to success. That’s why we always analyze the specific data we are dealing with; the right data provides the necessary information. Exploratory data analysis is the first step performed during a project.
Understanding the data is also helpful at intermediate stages:
- Before moving on to data cleaning, we collect information on missing values.
- Before transforming the data, we need to know what types of variables are in the set.
- Before starting the modeling process, we check for outlier observations and variables with unusual distributions.

Some algorithms are better suited for small data sets, while others can effectively handle large data sets and complex relationships between variables.
If you have a small data set with simple relationships between variables, algorithms such as linear regression or logistic regression may be sufficient. If you have a large data set with complex relationships, algorithms such as random forests or support vector machines may be more appropriate.
3. Interpretation vs. Performance
Another factor to consider is the trade-off between interpretability and efficiency. Some algorithms, such as decision trees, allow for interpretation, providing clear explanations for their predictions. Other algorithms, such as neural networks, may perform better but lack interpretability.
If interpretability is essential to your project, algorithms such as decision trees or logistic regression are good choices. If performance is the main goal and interpretability is not a priority, neural networks or deep learning models may be more appropriate.
4. The Complexity of the Algorithm
The complexity of the algorithm is also an essential factor. Some algorithms are relatively simple and easy to implement, while others are more complex and require advanced programming skills or computing resources.
If you have limited programming skills, algorithms such as linear regression or decision trees are a good starting point. If you have more advanced programming skills and computing resources, you can explore more complex algorithms, such as neural networks or deep learning models.
Given these factors, you can narrow your options and choose the suitable machine learning algorithm for your project. Experimenting with different algorithms and evaluating their performance for your specific task and data is important.
Division of Algorithms in Machine Learning
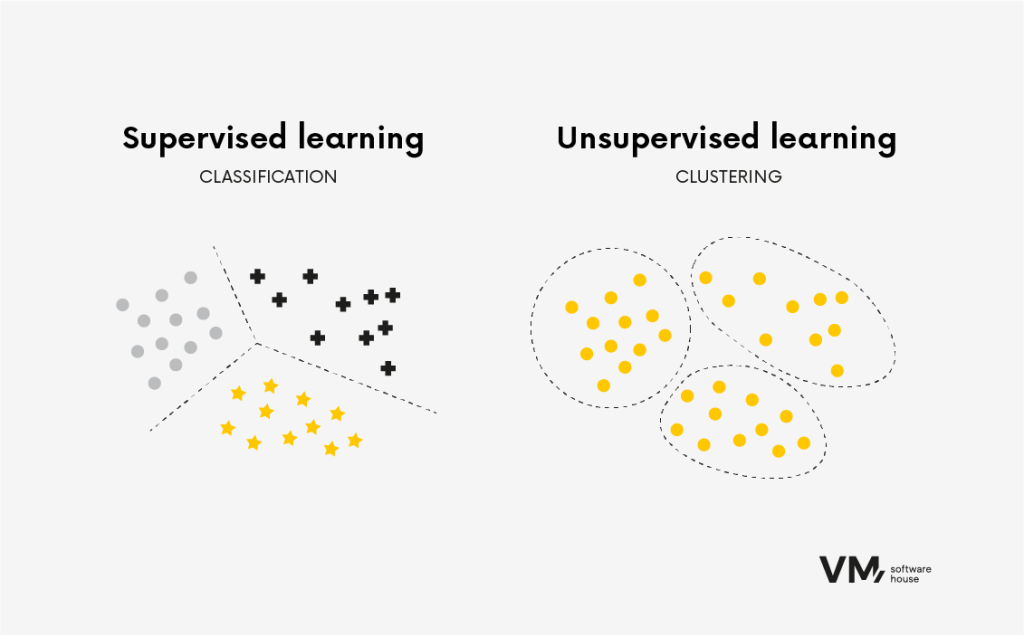
The most general way to divide algorithms is based on the type of learning: supervised and unsupervised.
Supervised Learning
Supervised learning algorithms are trained on labeled data, where the input data is associated with the correct output or target variable. The algorithm learns to assign input data to the proper output data by finding patterns and relationships in the data. This type of algorithm is commonly used in tasks such as classification and regression.
We use algorithms, such as regression, to predict a numerical value based on input characteristics. This value could be, for example, the estimated creditworthiness, the fraud risk for a selected transaction, or a binary value indicating whether a given bank customer will be a good or bad borrower. In summary, in this case, we know exactly what we are looking for and what we will base our decisions on.
An example would be a dataset of bank customers, described by variables such as date of birth, ID number, account balance, home address, credit history data, transaction history, etc.
Unsupervised Learning
Unsupervised learning algorithms are trained on unlabeled data, where only input data is available without a corresponding output or target label. The goal of unsupervised learning is to discover hidden patterns or structures in the data. These algorithms are beneficial when the data’s underlying structure is unknown.
We often use unsupervised learning algorithms for tasks such as clustering and dimensionality reduction. For example, in clustering tasks, the algorithm groups similar data points based on their internal similarities. This is useful for tasks such as customer segmentation, where the algorithm can identify groups of customers with similar preferences or behaviors.

Popular Machine Learning Algorithms
Machine learning algorithms come in many forms and formats, each with unique characteristics. In this section, we will discuss some popular algorithms and their applications in various industries.
1. Binary Classification
In classification tasks, the algorithm learns to classify input data into two predefined categories or classes.
Classification is used in situations such as object detection, various kinds of automation, and counting objects. It is also used in medical fields, such as detecting changes in medical imaging to distinguish between a sick person and a healthy person.
Binary classification involves training an algorithm to assign input data to two predetermined categories or classes. For example, a supervised learning algorithm can be trained to determine whether an email is spam or not by analyzing a labeled email dataset. Binary classification is commonly used because it allows us to sift through a given dataset and separate it into two groups.
What questions do classification algorithms answer? For example:
- Will the customer be a good borrower? (Will they repay the loan in full without significant delays?) | 0/1 (yes or no).
- Will a given customer want to cancel our services? | 0/1 (yes or no).
- Is the transaction fraudulent? | 0/1 (yes or no).
2. Multi-class Classification
Multi-class classification is similar to binary classification but involves predicting a single outcome from more than two classes. Sometimes, we want to differentiate between more complex categories. For example, in distinguishing diseases, we might want to know which cancer grade it is, what stage it is in, or determine a specific type of cancer from multiple types.

In the image above, we see the application of algorithms under supervision. The methods used are:
- Classification – Using classification, we can identify that in the picture, there is a dog, there are plush toys, and there is a cup.
- Object Discovery – We want to find a dog or a specific mug. This method allows us to determine the object’s boundaries (rectangle) and the probability that this specific object is in the frame.
- Segmentation – This method attempts to find and then mark individual objects as precisely as possible, separating them from each other.
- Semantic Segmentation – This method marks objects of the same type as one object.
3. Linear regression
Linear regression is a linear equation that determines the relationship between different dimensions.
The algorithm learns to find the best-fitting line that minimizes the sum of squared errors between predicted and actual values. It is often used in numerical prediction. For example, an algorithm can predict the value of a house based on characteristics such as its location, number of bedrooms, and area.
Linear regression is widely used in finance, economics, and the social sciences to analyze relationships between variables and make predictions. For instance, it can be used to predict stock prices based on historical data.
4. Logistic Regression
Logistic regression is a popular algorithm for predicting a binary outcome, such as “yes” or “no,” based on previous data set observations.
It determines the relationship between a binary dependent variable and one or more independent variables by fitting a logistic function to the data. The algorithm learns to find the best-fitting curve that separates two classes.
Logistic regression is widely used in marketing, healthcare, and social sciences to predict churn, detect fraud, and diagnose diseases. For example, it can be used to predict whether a customer is likely to abandon a purchase based on past behavior or to diagnose whether a patient has a particular disease based on their symptoms and medical history.
5. Decision Trees
Decision trees are versatile algorithms that can be used for both classification and regression tasks. They divide data into subsets based on input feature values and make predictions by traversing the tree from root to leaf node. The advantage of decision trees is the interpretability of the prediction results.
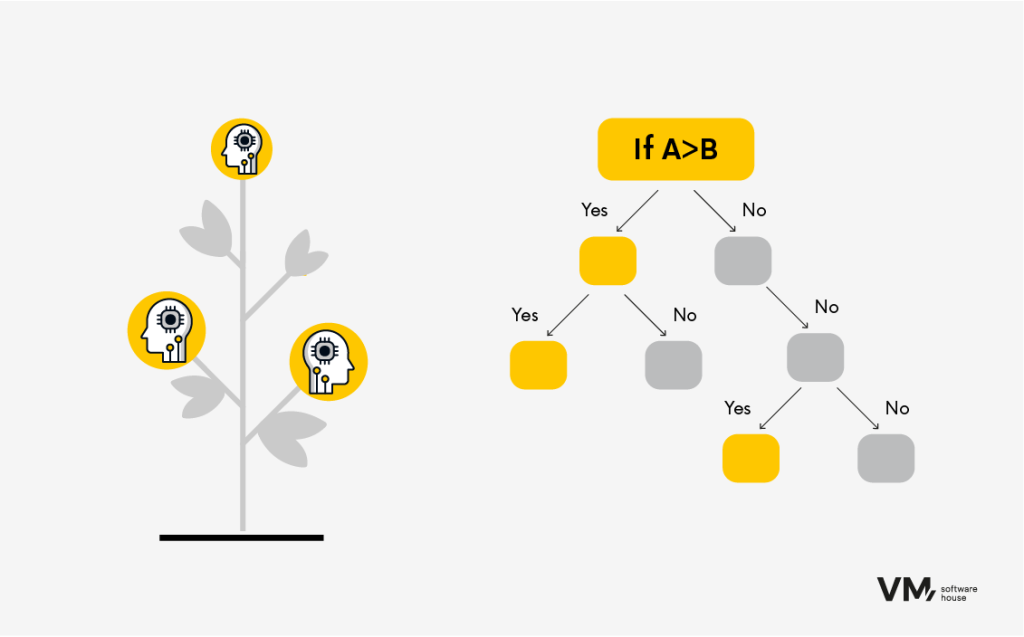
Example:
You have the test results. Want to learn more?
- Gender separation: female or male? Are you a woman? Go to the section below.
- Division by age. Divide, for example, into five different age ranges:
- 0-18 years old
- 18-25 years old
- 25-40 years old
- 40-55 years old
- 55-65 years old
3. Division by feature of the test result (determination of the level of a given result). The algorithm directs you step by step until you reach the last level, after which the final result is determined and named accordingly.
Decision trees learn relatively quickly and do not require a lot of computing power. However, for an algorithm to know how to build this tree automatically and be able to “pore over” the appropriate levels, it requires a sufficiently large amount of data so that any errors are as minor as possible.
These algorithms are widely used in finance, marketing, and e-commerce for creditworthiness assessment, customer segmentation, and product recommendation tasks. For example, a decision tree can predict whether a customer is creditworthy based on their income, age, and credit history or recommend products to customers based on their past purchases.
6. Boosted Decision Tree
This algorithm is used for both classification and regression tasks. It employs the concept of ensemble learning, where multiple weak learning algorithms (such as shallow decision trees with only a few levels) are combined to create a more accurate prediction. Progressive amplification allows predictive models to be built sequentially, with each tree aiming to predict the error left by the previous tree. This creates a sequence of trees. The result is a highly accurate algorithm that, nevertheless, requires a significant amount of memory.
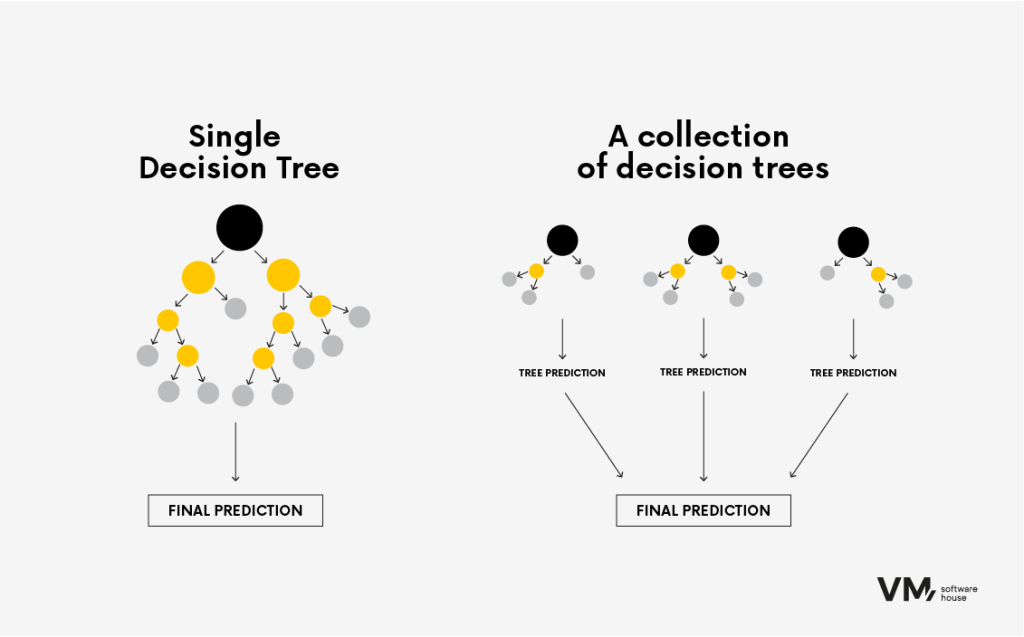
Boosted Decision Tree, for example, is used in investment banking or credit risk assessment systems—wherever accuracy counts, there are no limiting resources, or the algorithm does not need to be updated frequently.
7. Random Forest
The Random Forest algorithm is a popular machine learning technique used for classification and regression tasks. It belongs to ensemble learning methods, where multiple decision trees are built during training and combined to make a more accurate and stable prediction.
It’s like bringing together a group of diverse experts to make a decision. Each model contributes its insights, and together, they achieve better performance than any single model. The main advantage of Random Forests is that the model is more accurate than a decision tree because the more diverse the source of information, the more robust the Random Forest is. A single anomalous data source will not significantly influence it.
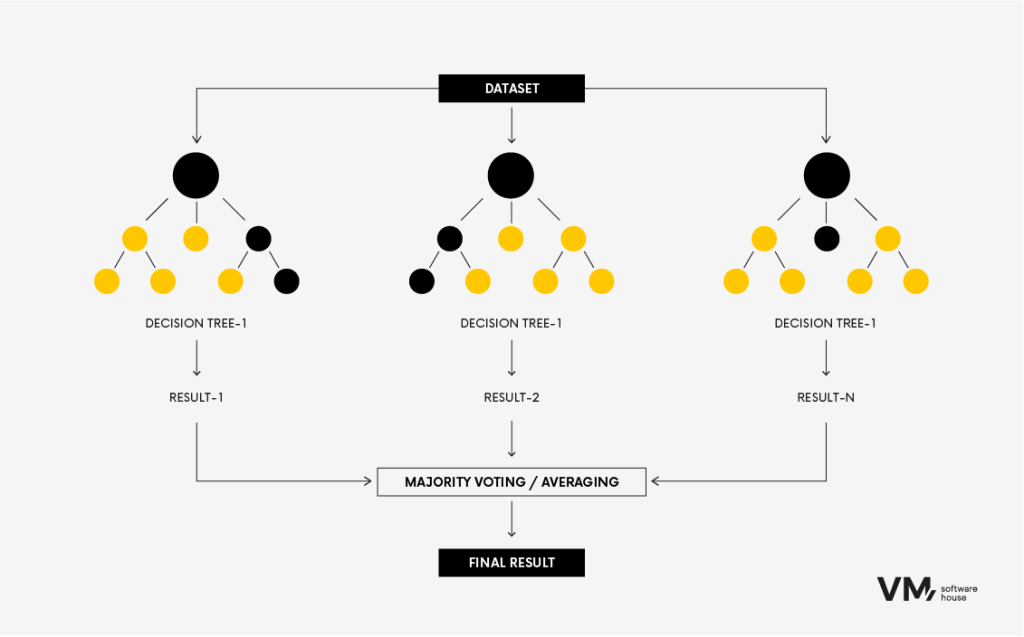
This method’s downside is that it requires large data resources, making it computationally expensive. It is most often used in investment banking or credit risk assessment systems.
Are you interested in Artificial Intelligence? Read the article: How AI Enhances Business Process Efficiency Through Data Analysis and Risk Assessment
8. Neural Networks
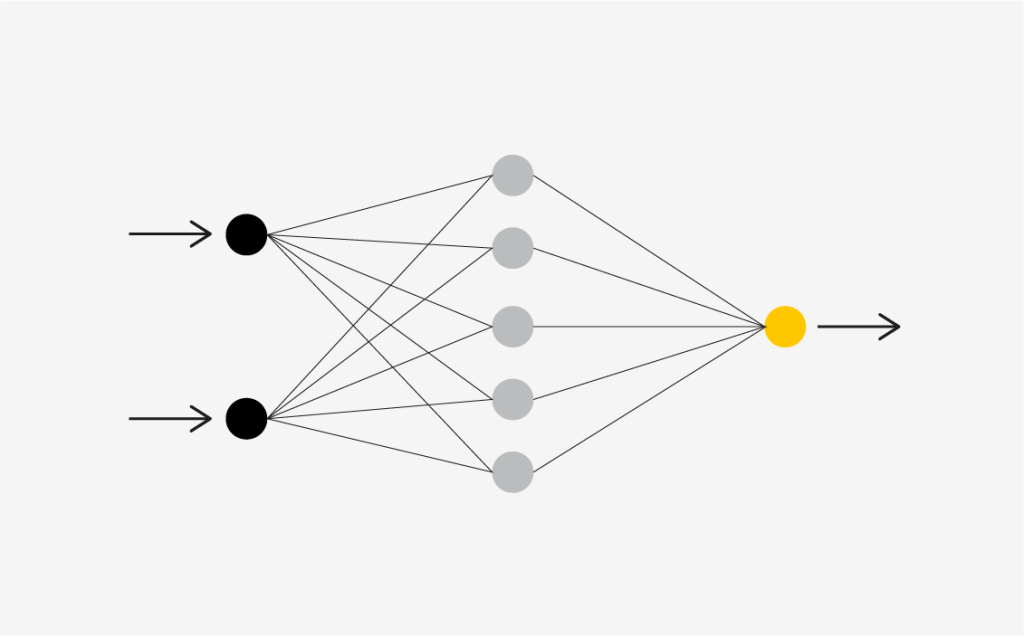
Neural networks are built using artificial brain cells called units. These units work together to learn, recognize patterns, and make decisions like the human brain. The way neural networks function can be likened to combining the power of a computer with densely connected brain cells.
Method of Operation
Computers use transistors—small switching devices. Modern microprocessors contain over 50 billion transistors, which are connected in relatively simple serial chains. The transistors are connected in basic circuits known as logic gates. Neural networks mimic the connections of real neurons by connecting artificial brain cells (units) in layers.
This method is most often used for complex problems with large data sets, particularly in problems where it is difficult to see simple patterns. Its main advantage is that it can learn complex patterns and is suitable for deep learning tasks. On the other hand, its disadvantage is that it requires significant computing resources (GPU) and extensive training data.
Neural networks are used in various fields:
- Image Recognition: Identifying and finding objects in images.
- Natural Language Processing: Understanding and generating human language.
- Recommendation Systems: Providing personalized suggestions (e.g., Netflix recommendations).
- Medical Diagnostics: Detecting diseases from medical images.
- Financial Forecasts: Predicting stock market trends, credit risk assessment, etc.
The Future of Predictive Analytics
Predictive analytics models play a vital role in forecasting by analyzing vast amounts of historical data, allowing organizations to predict future performance with a high degree of accuracy.
These models form the basis for strategic decision-making and operational optimization across industries. Whether it’s streamlining restaurant sanitation inspections, solving complex business challenges, or adjusting marketing strategies, the ability to predict future performance represents a significant advance in how data drives progress and innovation.
By implementing machine learning algorithms, you can make accurate predictions based on new, unseen data. It is important to regularly iterate and refine the process to meet the specific requirements of a project. If you would like to discuss this with AI/ML specialists, feel free to contact us.
Design, Development, DevOps or Cloud – which team do you need to speed up work on your projects? Chat with your consultation partners to see if we are a good match.
Jakub Orczyk
Member of the Management Board/ Sales Director VM.PL
Book a free consultation